Overcoming JavaScript Scraping Challenges with Modern Tools: A Personal Case Study

Scraping websites has never been as challenging as it is today. While static sites used to dominate the web, the explosion of JavaScript-heavy frameworks like React, Vue.js, and Angular has made data extraction significantly more complicated. Over the years, I’ve faced various obstacles trying to scrape dynamic content, and the evolution of web technologies has forced me to continuously adapt my approach.
This case study explores how I tackled JavaScript-heavy websites using modern tools and how I eventually succeeded in collecting meaningful data efficiently, overcoming challenges such as dynamic content rendering, authentication, and anti-bot measures.
The Problem: Scraping JavaScript-Heavy Websites
Several years ago, I was tasked with scraping product data from a popular e-commerce site. At first glance, it seemed like a straightforward project—get the product name, price, availability, and customer reviews. However, after examining the page’s source code, I realized that most of the content was not available in the HTML.
Instead, the data I needed was dynamically loaded via JavaScript after the initial page load. The e-commerce site used React to fetch and render products asynchronously, making traditional scraping tools like Cheerio ineffective.
I was stuck with an incomplete page, wondering how to extract all the necessary data. That's when I knew I needed to upgrade my approach.
Strategy #1: Reverse-Engineering API Calls
Before diving into complex browser automation, I always check if a website has an API I can tap into. In this case, the e-commerce site was using internal APIs to fetch product data in JSON format. By inspecting the network traffic using Chrome DevTools, I discovered the API endpoints that served the exact data I needed.
Here’s how I reverse-engineered the API:
- I opened the site and navigated to the Network tab in Chrome DevTools.
- After refreshing the page, I filtered the requests to show only
XHRandFetchrequests. - I found the API that returned product data in JSON format, which included names, prices, and reviews.
- Using
Postmanorcurl, I tested these API endpoints outside the browser, tweaking parameters like product IDs and pagination.
By sending HTTP requests directly to these API endpoints, I was able to gather all the product data I needed without ever interacting with the rendered JavaScript. This approach worked well because:
- It was fast: API requests are faster than rendering full pages in a headless browser.
- It was efficient: JSON responses were lightweight and easy to parse.
However, not all websites expose their APIs so clearly. That’s where modern scraping tools come into play.
Strategy #2: Using Puppeteer for Browser Automation
For websites that rely heavily on JavaScript without exposing APIs, I turned to Puppeteer, a powerful headless browser. Puppeteer allows you to programmatically control a browser, letting you scrape data from websites that require JavaScript to load fully.
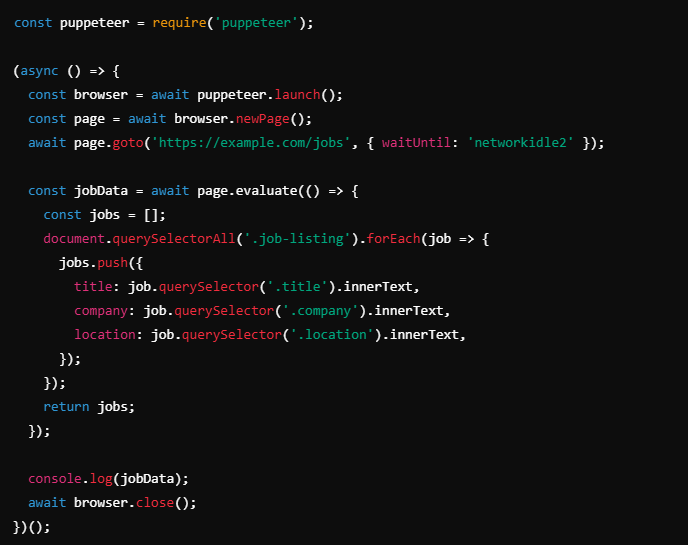
In another project, I was scraping job listings from a startup platform that dynamically rendered its listings with React. There was no API available, so I needed to simulate a real browser session. Here’s how Puppeteer saved the day:
- I launched a headless browser instance and navigated to the job listings page.
- Puppeteer waited until all network requests were complete, ensuring that the page fully loaded.
- Using
page.evaluate(), I extracted the job data (title, company, location, etc.) directly from the rendered HTML.
Why Puppeteer?
Puppeteer provides several advantages:
- Full Control: I could wait for specific elements to load before scraping, ensuring I didn’t miss any data.
- Handling Complex Workflows: Some websites require user interactions (clicking buttons, scrolling to load more content). Puppeteer handled this with ease.
- Visual Feedback: I could take screenshots to verify that pages were rendering as expected.
Despite its flexibility, Puppeteer does have one downside—it can be slower than API-based scraping since it requires rendering full pages. However, for JavaScript-heavy sites, it’s an invaluable tool.
Strategy #3: Avoiding CAPTCHAs and Anti-Bot Measures
As scraping tools have improved, so have the anti-bot measures websites use. Many sites today employ CAPTCHAs, IP blocking, and other methods to prevent automated scraping.
One particularly challenging project involved scraping a directory of professionals from a website that required CAPTCHA solving after every few requests. To get around this, I used a combination of techniques:
- Rotating Proxies: By using a pool of proxies, I avoided rate-limiting and reduced the chance of being flagged as a bot.
- CAPTCHA Solvers: Services like
2CaptchaandCAPTCHABeeallowed me to automate the solving of CAPTCHAs, though this added some cost and complexity to the process. - Browser Fingerprinting: I ensured that my headless browser mimicked a real user by setting custom user agents, enabling JavaScript, and randomizing mouse movements and clicks.
By combining these tactics, I was able to complete the scraping project without getting banned or blocked.
Strategy #4: Scraping JavaScript-Heavy Pages with Playwright
More recently, I started using Playwright, an advanced browser automation tool that builds on Puppeteer’s foundation. What sets Playwright apart is its support for multiple browsers (Chromium, Firefox, WebKit) and better handling of complex interactions like file downloads, dialogs, and multi-page workflows.
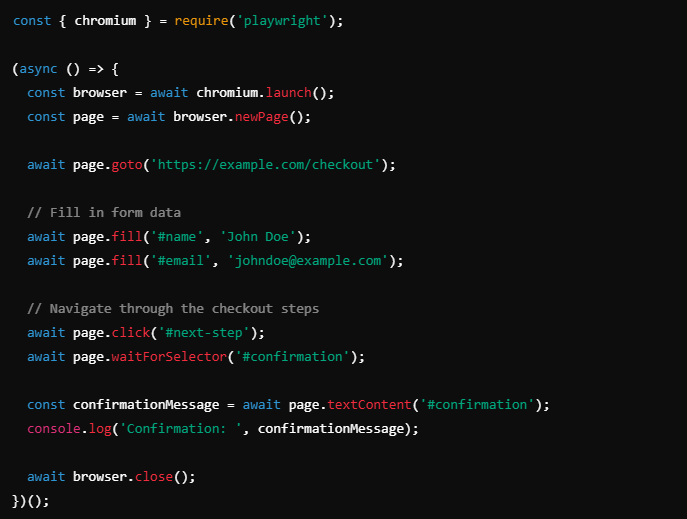
In one project, I needed to scrape a multi-step checkout process on an e-commerce website. The website required the user to navigate through several pages, fill out forms, and complete CAPTCHA challenges. Playwright’s ability to handle these complex workflows in different browser environments made it the perfect choice.
Here’s a sample Playwright script to scrape such a multi-step form:
Playwright has now become my go-to tool for more complex web scraping tasks, especially when handling multiple browsers or mimicking user behavior across different environments.
Lessons Learned and Best Practices
Through my journey scraping JavaScript-heavy websites, I’ve learned several valuable lessons:
- Always Check for APIs First: API scraping is faster, simpler, and more efficient. Always check the network requests for available APIs before resorting to browser automation.
- Use the Right Tool for the Job: While Puppeteer and Playwright are powerful, they can be overkill for simpler sites. Balance the complexity of the site with the tools you use to scrape it.
- Manage Resources Carefully: Headless browsers consume significant CPU and memory. Running many instances in parallel can overload your system, so always optimize and monitor resource usage.
- Be Ethical: Respect websites’ terms of service, and always scrape responsibly. Use proxies, avoid overloading servers, and implement delays between requests when necessary.
Conclusion
Scraping JavaScript-heavy websites is no small feat, but with the right tools and strategies, you can extract valuable data even from the most dynamic sites. Whether through reverse-engineering APIs, using headless browsers like Puppeteer and Playwright, or employing advanced techniques to bypass anti-bot measures, modern web scrapers have a variety of tools at their disposal. By adapting to the ever-changing landscape of web technologies, you can stay ahead and scrape data efficiently, ethically, and at scale.



